Autorské riešenie
Pri tejto úlohe musíme myslieť na dve veci.
V takýchto prípadoch môžeme postupovať tak, že najskôr vytvoríme nejaké správne riešenie a potom ho budeme postupne vylepšovať (ak sa bude dať a budeme vedieť ako). Tento prístup má aj dve výhody:
Vytvorme si správne riešenie. Postupovať môžeme tak, ako je uvedené v zadaní:
Vytvorme si najskôr funkciu pre výpočet mediánu v usporiadanej podpostupnosti: # Python def median(podpostupnost): dlzka = len(podpostupnost) if dlzka % 2 == 0: return (podpostupnost[dlzka // 2 - 1] + podpostupnost[dlzka // 2]) / 2 return podpostupnost[dlzka // 2] Túto funkciu volajme pre jednotlivé usporiadané podpostupnosti celej postupnosti hodnôt. # Python def klzavy_median_1(postupnost, dlzka): mediany = [] for index in range(len(postupnost) - dlzka + 1): podpostupnost = postupnost[index:index + dlzka] podpostupnost.sort() mediany.append(median(podpostupnost)) return mediany Teraz máme funkčné a správne riešenie. Pozrime sa, či by sa nedalo nejako vylepšiť. Všimnime si, ako pracujeme s jednotlivými podpostupnosťami. Podpostupnosť usporiadame. Ďalšia podpostupnosť sa od predchádzajúcej líši len tím, že jeden prvok sme z nej odstránili a jeden prvok sme do nej vložili. Mohli by sme teda nejako využiť to, že po odstránení prvku je podpostupnosť stále usporiadaná. Vložiť prvok do usporiadanej podpostupnosti vieme spraviť aj bez toho, aby sme ju nanovo usporadúvali. Pozíciu vkladaného prvku vieme nájsť priamo. Postupovať môžeme takto:
Výsledkom je, že nájdeme pozíciu kam je potrebné vložiť nový prvok. Podpostupnosti teda nemusíme vždy nanovo usporadúvať. Toto riešenie môže vyzerať nasledovne: # Python def median(podpostupnost): dlzka = len(podpostupnost) if dlzka % 2 == 0: return (podpostupnost[dlzka // 2 - 1] + podpostupnost[dlzka // 2]) / 2 return podpostupnost[dlzka // 2] def najdi_poziciu(hodnota, podpostupnost): lavy = 0 pravy = len(podpostupnost) - 1 while lavy <= pravy: stred = (lavy + pravy) // 2 if podpostupnost[stred] == hodnota: return stred if hodnota < podpostupnost[stred]: pravy = stred - 1 else: lavy = stred + 1 return lavy def klzavy_median_2(postupnost, dlzka): mediany = [] podpostupnost = postupnost[:dlzka] podpostupnost.sort() mediany.append(median(podpostupnost)) for index in range(len(postupnost) - dlzka): podpostupnost.remove(postupnost[index]) pridavany_prvok = postupnost[index + dlzka] pozicia_pridavaneho = najdi_poziciu(pridavany_prvok, podpostupnost) podpostupnost.insert(pozicia_pridavaneho, pridavany_prvok) mediany.append(median(podpostupnost)) return mediany Naše riešenie sme vylepšili, pretože nemusíme nové podpostupnosti vždy usporadúvať. Skúsme ho vylepšiť ešte viac. Všimnime si, že keď z podpostupnosti odstraňujeme prvý pridaný prvok, použijeme príkaz zoznamu remove(). Aby Python našiel v podpostupnosti prvok, ktorý chceme odstrániť, musí celú podpostupnosť prehľadať (presnejšie, kým prvok nenájde). Pozíciu prvku, ktorú má Python z podpostupnosti odstrániť vieme nájsť aj šikovnejšie. Využijeme fakt, že podpostupnosť je usporiadaná a pre hľadanie pozícii už máme vytvorenú funkciu najdi_poziciu(). Riešenie s týmto vylepšením môže vyzerať nasledovne: # Python def median(podpostupnost): dlzka = len(podpostupnost) if dlzka % 2 == 0: return (podpostupnost[dlzka // 2 - 1] + podpostupnost[dlzka // 2]) / 2 return podpostupnost[dlzka // 2] def najdi_poziciu(hodnota, podpostupnost): lavy = 0 pravy = len(podpostupnost) - 1 while lavy <= pravy: stred = (lavy + pravy) // 2 if podpostupnost[stred] == hodnota: return stred if hodnota < podpostupnost[stred]: pravy = stred - 1 else: lavy = stred + 1 return lavy def klzavy_median_3(postupnost, dlzka): mediany = [] podpostupnost = postupnost[:dlzka] podpostupnost.sort() mediany.append(median(podpostupnost)) for index in range(len(postupnost) - dlzka): pozicia_odstranovaneho = najdi_poziciu(postupnost[index], podpostupnost) podpostupnost.pop(pozicia_odstranovaneho) pridavany_prvok = postupnost[index + dlzka] pozicia_pridavaneho = najdi_poziciu(pridavany_prvok, podpostupnost) podpostupnost.insert(pozicia_pridavaneho, pridavany_prvok) mediany.append(median(podpostupnost)) return mediany Pozrime sa ešte na to, ako "úspešné" sú naše vylepšenia. Namiesto teoretickej analýzy otestujme rýchlosť našich funkcií. Testov by sme mali realizovať niekoľko, aby záver bol čo najmenej ovplyvnený nejakou náhodou, ktorá sa vyskytla práve v čase testovania niektorej z funkcií. Zároveň uvažujme veľké množstvá dát, lebo pri malých množstvách nemusí byť úspora tak dobre viditeľná. Len pre ilustráciu. Otestovali sme rýchlosť našich funkcií niekoľko krát pre rôzne dlhé postupnosti a rôzne dlhé podpostupnosti. Každú funkciu sme spustili 30x a v tabuľke uvádzame priemerný čas jej behu:
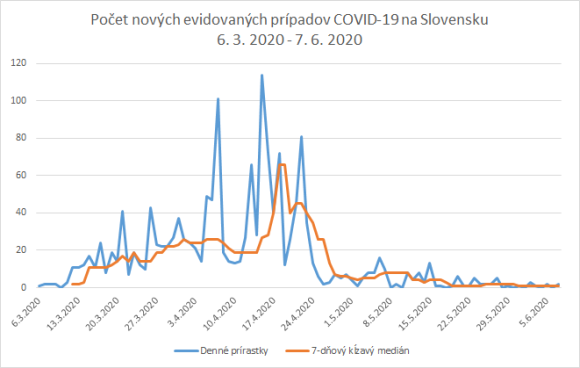
Pri malých dĺžkach podpostupností sú uvedené funkcie +- rovnako rýchlo. Rozdiel sa začne prejavovať pri väčších dĺžkach podpostupností. Zoberme si toto poučenie aj do budúcnosti. Ak navrhujeme nejaké riešenie, uvažujme o "veľkých" vstupoch. Až tam sa začne prejavovať efektivita našich algoritmov. Na záver uvádzame jedno praktické využitie kĺzavého mediánu. Nasledujúci graf zobrazuje nové evidované prípady ochorenia na COVID-19 na Slovensku a 7-dňový kĺzavý medián. Z obrázku je viditeľné, že kĺzavý medián nie je ovplyvnený lokálnymi extrémnymi hodnotami, takže je z neho lepšie viditeľný trend vývoja počtu ochorení.
A ešte jedno malé, možno pre niekoho prekvapivé zamyslenie. Pri končiacich opatreniach v súvislosti s COVID-19 na Slovensku sme často počuli, že 7-dňový kĺzavý medián pre nové potvrdené prípady ochorenia má hodnotu 0. Aký môže byť v skutočnosti počet nových prípadov? Aký je 7-dňový kĺzavý medián pre postupnosť hodnôt? [1000, 0, 1000, 0, 1000, 0, 0, 1000, 0, 1000, 0, 1000, 0, 0, 1000, 0, 1000, 0, 1000, 0, 0, 1000] Vaše zaujímavé riešenia a najčastejšie chyby Všetky tímy, ktoré túto úlohu riešili odovzdali správne riešenie. Rozdiel bol len v efektívnosti jednotlivých riešení. Väčšina riešení sa spoľahla na vstavané funkcie a metódy zoznamov, podobne ako vyššie uvedené riešenie klzavy_median_1(). Našli sa však aj dva tímy (HairyElephants, seesharp) ktoré využili binárne vyhľadávanie (viď funkcia najdi_poziciu()) a zvýšili tak efektívnosť riešenia. Na jednej strane je pre programátora výhodné využívať funkcionalitu, ktorú mu daný programovací jazyk poskytuje. Na druhej strane si treba uvedomiť, či pre uvedené potreby nevieme nájsť efektívnejšie riešenie. Namiesto sústavného usporadúvania (zoznam.sort()) udržujme zoznam usporiadaný. Namiesto mazania prvku (zoznam.remove()) využime fakt, že zoznam je usporiadaný a nájdime pozíciu mazaného prvku priamo. |
||||||||||||||||||||||||||||||||||||||||
|
© Univerzita Pavla Jozefa Šafárika v Košiciach, Prírodovedecká fakulta, Ústav informatiky palmaj (zavinac) upjs.sk |
||||||||||||||||||||||||||||||||||||||||